Uber builds multi-sided marketplaces handling millions of trips every day across the globe. We strive to build real-time experiences for all our users.
The nature of real time marketplaces make them very lively. Over the course of a trip, there are multiple participants that can modify and view the state of an ongoing trip and need real-time updates. This creates the need to keep all active participants and apps synced with real-time information, whether it’s through pickup time, arrival time, and route lines on the screen, or nearby drivers when you open the app.
A key dimension of growth was feature explosion in critical user screens and the need for developers across the company to build real-time mobile features in a decentralized way on a shared app screen.
This article describes how we went from polling for refreshing the app to a gRPC-based bi-directional streaming protocol to build our app experience.
An Uber trip is an orchestration between participating entities like the riders and drivers moving in the physical world. These two entities need to stay updated with backend systems and each other as the trip progresses.
Consider a scenario where a rider has requested a ride and a driver is online to provide a service. Uber’s matching system in the backend identifies a match and provides a trip offer to a driver. Now everyone (rider, driver, backend) should be synchronized with each other’s intent.
The driver app can poll the server every few seconds to check if a new offer is available. The rider app can poll the server every few seconds to check if a driver is assigned.
The frequency of the polling of these apps depends on the rate of change of the data that they are polling for. In a large app like the Uber app, the variation of the rate of change is very wide ranging from seconds to hours.
At some point, 80% of requests made to the backend API gateway were polling calls.
Aggressive polling keeps the app responsive, but leads to larger server resource utilization. Any bugs in the polling frequency results in significant backend load and degradation. As the number of features with real-time dynamic data needs increased, this approach was infeasible as it would continue to add significant load on the backend.
Polling leads to faster battery drain, app sluggishness, and network-level congestion. This is especially evident in places with 2G/3G networks or spotty networks across the city where the app retries multiple times for each polling attempt.
As the number of features grew, developers tried to either overload existing polling APIs or create a new one. At its peak, the app was polling dozens of APIs. Each API was overloaded with multiple features. These polling APIs ultimately just became a set of payload sharded APIs for the app to poll its features. Maintaining consistency and logical separation of concern at the API level continued to be a growing challenge.
Cold startup of an app was the most challenging scenario for a polling strategy. Every time the app was opened, all the features wanted to pull the latest state from the backend to render the UI. This led to multiple competing concurrent API calls and the app could not render until critical components were retrieved from the server. Without prioritization, because all the APIs had some pieces of the critical information, app load time continued to increase. Poor network conditions would further exacerbate the cold startup problem.
It was clear that we needed a complete revamp in how we sync state across various participants in the marketplace. We embarked on a journey to build a push messaging platform with the ability for the server to send data to the app on demand.
As we adopted this architecture we found significant efficiency improvements, but also tackled different sets of problems and challenges. In the next section, we describe different generations of our push infrastructure and how this platform evolved.
While using push messaging was a natural choice to eliminate polling, there were a lot of considerations on how to architect this. The four main design principles are the following.
Easier migration from polling to push
There were many existing polling endpoints that powered the business. The new system had to leverage the payload building business logic in the existing polling APIs without the need to rewrite them all.
Ease of development
A developer should not be doing drastically different things to push data relative to their effort to develop a polling API.
Reliability
All messages should be sent reliably over the network and retried if delivery fails.
Wire efficiency
With Uber growing rapidly into developing countries, the cost of data usage was a challenge for our users, this is especially true for drivers who are connected to the platform for multiple hours a day. The protocol had to minimize the amount of data transfer between server and mobile apps.
We named the new system RAMEN (Realtime Asynchronous MEssaging Network).
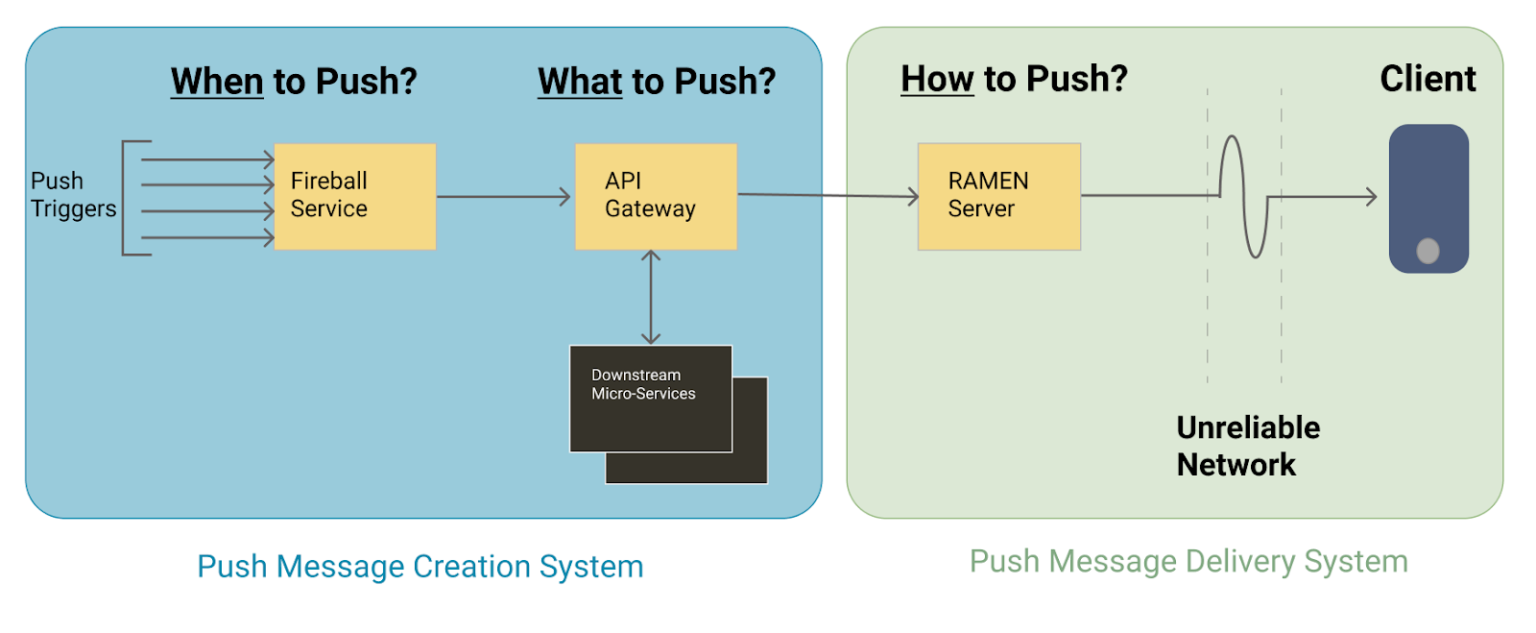
Figure 1: High-level architecture of the overall system.
At any given moment, real-time information is changing across hundreds of riders, drivers, restaurants, eaters, and trips. The lifecycle of a message starts with deciding on “when” to generate a message payload for a user.
Fireball is a microservice responsible for solving the problem of “when to push a message?” A large part of the decision is captured as configurations. It listens to various types of events happening across the system and determines if a push is necessary for involved users.
As an example, when a driver “accepts” an offer, the driver and trip entity state changes. This change triggers the Fireball service. Then, based on a configuration, Fireball decides what type of push messages should be sent to the involved marketplace participants. Very often, a single trigger would warrant sending multiple message payloads to multiple users.
A trigger can be any kind of significant event for which push payload should be generated. For example, a user action like requesting a ride, the app opening, a timer ticking on a fixed interval, a backend business event on the message bus, or geographic egress/ingress events.
All such triggers are filtered and translated into calls to various API gateway endpoints. The API getaway needs user context information like device locale, device operating system and app version to generate the appropriately localized response payload. Fireball fetches the device context RAMEN Server and adds them to the headers when making the call to the API gateway.
All server calls originating from Uber apps are served by our API gateway (read more about the evolution of our gateways here). Push payloads are generated in the same way.
The API gateway is responsible for determining “what to push” once Fireball determines who and when to push a message. The gateway calls various domain services to generate the correct push payload.
All APIs in a gateway are anatomically similar on how they generate a payload. However, the APIs are categorized as Pull and Push APIs. Pull APIs are the endpoints called from mobile devices to do any of the HTTP operations. Push APIs are endpoints called from Fireball and have an extra “Push” middleware that can intercept the response of a pull API and forward it to the push message delivery system.
Putting your API gateway in between has advantages.
The pull and push APIs share most of the business logic of the endpoints. A given payload can be seamlessly switched from a pull API to a push API. Example, the same logic is used whether your app is pulling a “user” object via a pull API call or Fireball is sending a “user” object via a push API call.
The gateways take care of many cross-cutting concerns like rate limiting, routing, and schema validations of push messages.
Both Fireball and the gateway together generate the push messages to be sent to the user at the appropriate time. Delivering this to mobile devices is a responsibility of the “Push Message Delivery System.”
Each push message has various configurations defined for optimizations.
Priority
With hundreds of different payloads generated for various use cases there is a need for prioritization of what is to be sent to the app first. As we will see in the next sections, the protocol we adopted restricted sending multiple concurrent payloads on a single connection. Further, the bandwidth of the receiving device is limited.
To bring a sense of relative priority, messages were broadly categorized into three different priority buckets with an understanding of the impact:
This priority configuration was then used to govern various behaviors of the platform. For example, when a connection is established, messages are put in the socket in descending order of priority. High priority messages were made more reliable with server side retries in case of RPC failures and has support for cross region replication.
Time to live
Push messages were meant for improving real-time experiences. Hence each message has a defined time to live value ranging from a few seconds to up to 30 minutes. The message delivery system will persist the message and retry delivery of the message until the time to live value expires.
Deduplication
This configuration determines if a push message should be deduplicated in the case when the same message type is generated multiple times through various triggers or retries. For the majority of our use cases, sending the most recent push message of a given type was enough to satisfy the user experience and this allowed us to reduce the overall data transfer rate.
The final component of the push message system is the actual payload delivery service. The service that is maintaining active connections to millions of mobile apps around the world and concurrently federating message payloads to them as quickly as they arrive.
The mobile networks around the world provide varied levels of reliability, hence the delivery system needs to be robust to accommodate failures. Our system provides an “at-least-once” guarantee for delivery.
RAMEN delivery protocol To provide a reliable delivery channel we had to utilize a TCP based persistent connection from the apps to the delivery service in our datacenter. For an application protocol in 2015, our options were to utilize HTTP/1.1 with long polling, Web Sockets or finally Server-Sent events (SSE).
Based on the various considerations like security, support in mobile SDKs, and binary size impact, we settled on using SSE. Its simplicity and operability on the already supported HTTP + JSON API stack at Uber made it our choice at that time.
However, SSE is a unidirectional protocol, i.e., data can only be sent from the server to the app. To provide at-least-once guarantees mentioned before, there was a need for acknowledgments and retries to be built into a delivery protocol on top of the application protocol.
A very elegant and simple protocol scheme was defined on top of SSE.
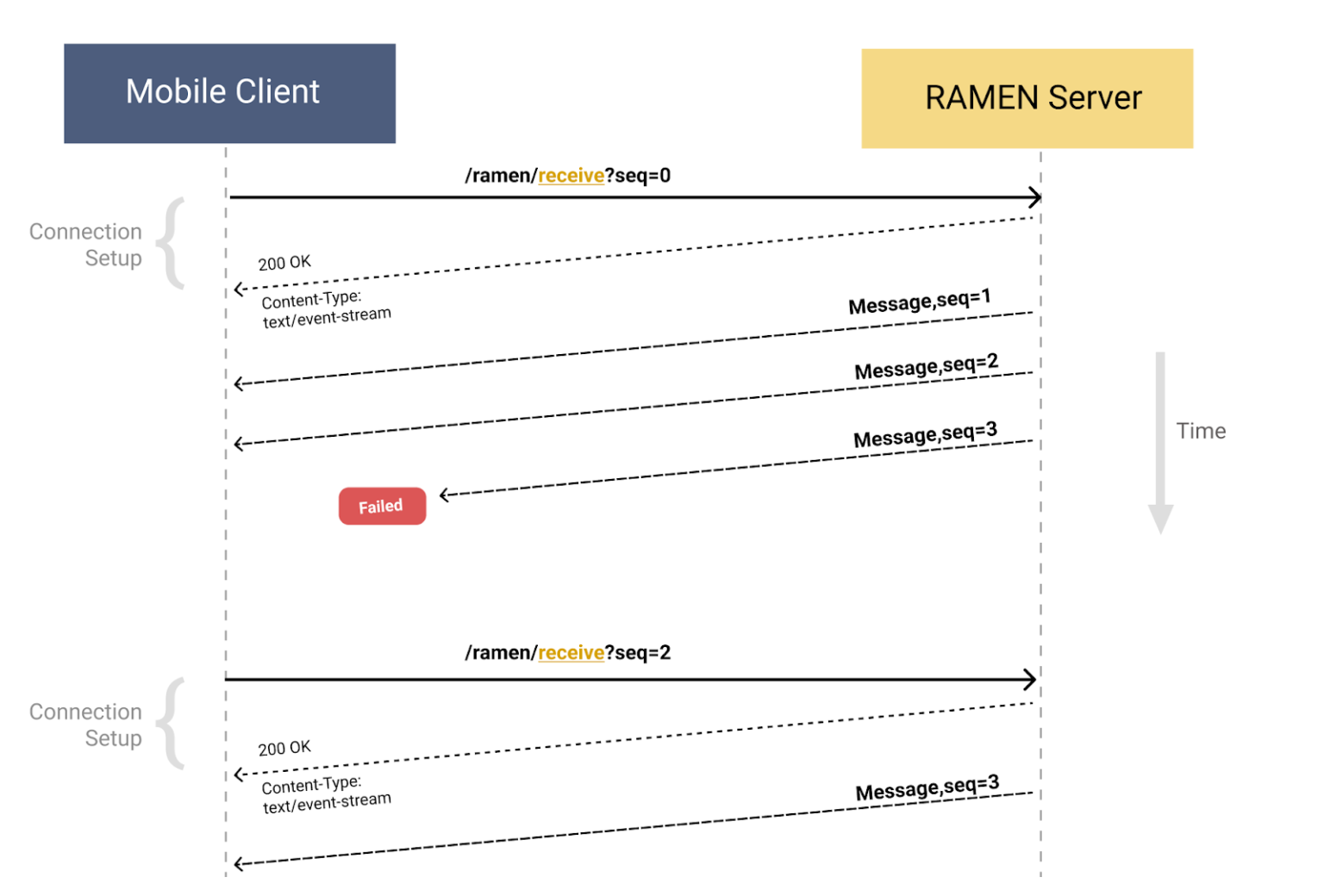
Figure 2: Server-client interaction for the SSE protocol.
The client starts receiving a message on a first HTTP request /ramen/receive?seq=0 with a sequence number of 0 at the beginning of any new session. The server responds with HTTP 200 and ‘Content-Type: text/event-stream’ for maintaining the SSE connection.
As the next step, the server sends all pending messages in the descending order of priority and associates incremental sequence numbers. Since the underlying transport protocol is a TCP connection, if a message with seq#3 is not delivered, then the connection should have disconnected, timed out, or failed.
The client is now expected to reconnect at next opportunity with the largest sequence number it has seen (seq=2 in this case). That tells the server that even though number 3 was written to the socket, it never got delivered. Then the server will resend that same message or any new higher priority message starting with seq=3. This protocol builds the required resumability of streaming connection with the server doing the majority of the storekeeping and is quite simple to implement on the client side.
To know if the connection is alive, the server sends a single byte sized heartbeat message every 4 seconds. If a client sees no heartbeat or a message up to 7 seconds, it assumes the connection is broken and reconnects.
In the above protocol, whenever a client reconnects with a higher sequence number, it acts as an acknowledgment mechanism for the server to flush older messages. On a good network, users may stay connected for up to a few minutes resulting in the server continuing to accumulate the older messages. To mitigate this issue, the app would call /ramen/ack?seq=N every 30 seconds regardless of the connection quality.
The simplicity of the protocol allowed writing clients in many different languages and platforms very quickly.
Device context storage
RAMEN Server additionally stores the device context every time a connection is established. This context is exposed to Fireball to access device contexts for a user. Each device context’s id was generated with a unique hash using the user & their device parameters. This allows isolation of push messages even when the user is using multiple devices or apps simultaneously with different settings.
Message storage
RAMEN servers hold all the messages either in memory and backed in a database. If the connection is flaky, the server can keep retrying to send until a TTL expiry.
This first generation of RAMEN server was written in Node.js using Uber’s in-house consistent hashing/sharding framework called “Ringpop.” Ringpop is a decentralized sharding system. All the connections were sharded with a user UUID and used Redis as the persistence data store.
Over the next year and a half, the push platform saw tremendous adoption across the company. At peak, this system pushed over 70,000 QPS push messages per second to three different types of apps by maintaining up to 600,000 concurrent streaming connections. This system quickly became the most integral part of the server client API infrastructure.
As the volume of traffic and persistent connections increased, our technology choices needed to scale as well. Ringpop-based distributed sharding is a very simple architecture, but does not scale as the number of nodes in the ring increases. The Ringpop library used a gossip protocol for evaluating membership. The time of convergence for the gossip protocol also increases as the size of the ring increases.
Additionally, Node.js workers were single threaded and would have elevated levels of event loop lag resulting in a further delay in the convergence of membership information. These issues could result in topology information that is inconsistent and lead to message loss, timeouts, and errors.
In early 2017, we decided that it was time for a reboot of the server implementation of RAMEN protocol to continue to scale. For this iteration we used the following technologies: Netty, Apache Zookeeper, Apache Helix, Redis and Apache Cassandra.
Netty: Netty is a widely used and high performance library to build network servers and clients. Netty’s bytebuf allows zero-copy buffers that make the system very efficient.
Apache ZooKeeper: Having a consistent hashing of network connections allows direct streaming of data without needing any storage layer in between. But, instead of a decentralized topology management, we chose centralized sharing with ZooKeeper. ZooKeeper is a very powerful system for distributed synchronization and configuration management and can detect failures of connected nodes quickly.
Apache Helix: Helix is a robust cluster management framework that works on top of ZooKeeper, allowing defining custom topologies and rebalancing algorithms. It also nicely abstracts out topology logic from the core the business logic. It uses ZooKeeper for monitoring of connected workers and propagating sharding state information change. It also allowed us to write a custom “Leader-Follower” topology and custom gradual rebalancing algorithm.
Redis & Apache Cassandra: As we were getting ready for multi-region cloud architecture, it was necessary that the messages were properly replicated and stored. Cassandra is a durable and cross region replicated storage. Redis was used as a capacity cache on top of Cassandra to avoid thundering herd problems commonly associated with the sharded systems on deployments or failover events.
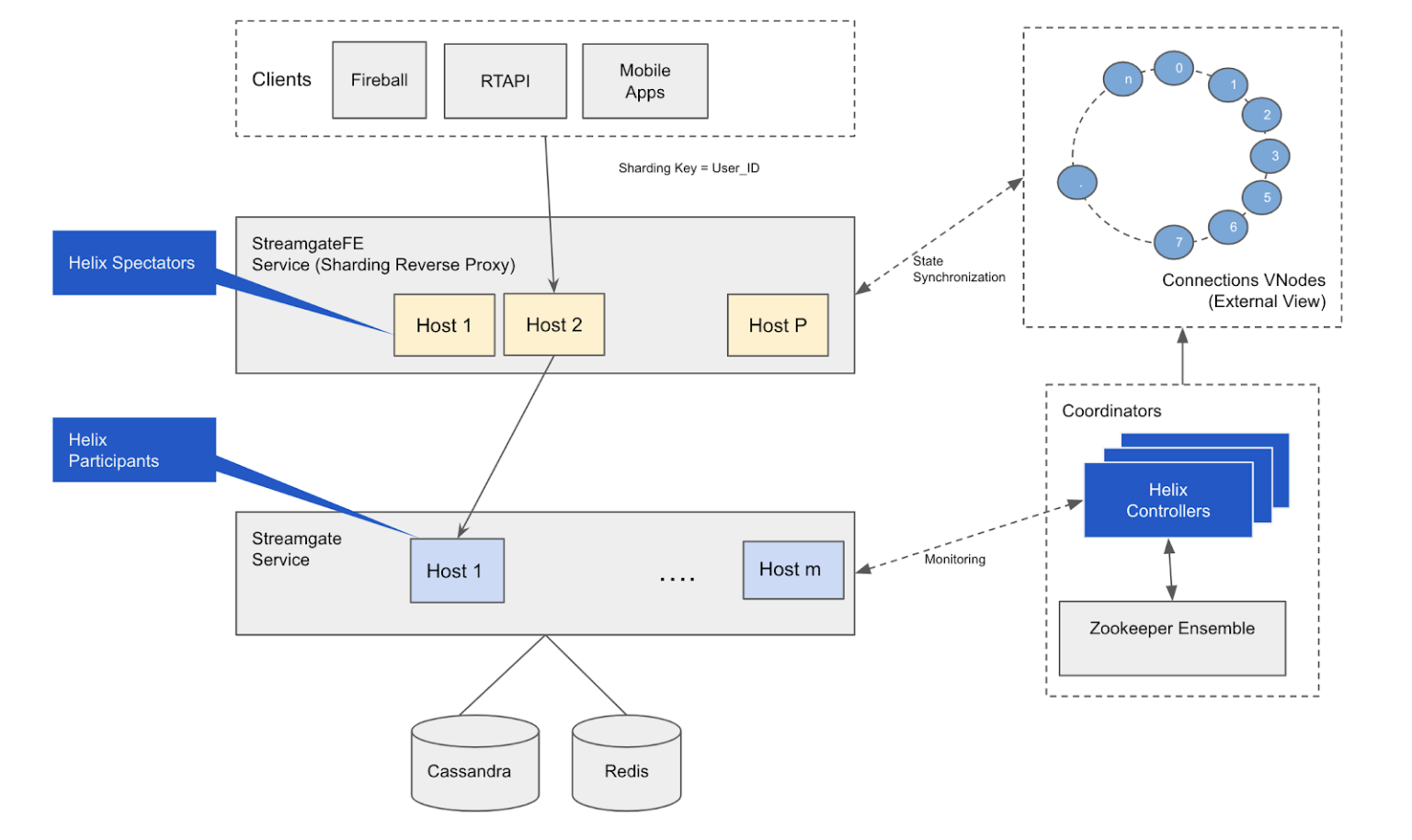
Figure 3: Architecture for the new RAMEN backend server.
Streamgate: This service implements the RAMEN Protocol on Netty and has all the logic related to handling connections, messages, and storage. This service additionally implements an Apache Helix participant that establishes connections with ZooKeeper and maintains heartbeats.
StreamgateFE (Streamgate Front End): This service acts as an Apache Helix Spectator and listens to topology changes from ZooKeeper. It implements a reverse proxy. Every request coming from clients—Fireball, gateway or mobile apps—are sharded using topology information and routed to the correct Streamgate worker.
Helix Controllers: As the name suggests, this is a five-node standalone service solely responsible for running Apache Helix Controller processes and is the brain of topology management. Whenever any Streamgate node starts or stops, it detects a change and re-allocates the sharding partitions.
We have been operating with this architecture for the last few years and were able to achieve 99.99% server-side reliability of the infrastructure. The adoption of this push infrastructure continues to grow, supporting more than ten different types of applications on iOS, Android and Web platforms. We have operated this system with more than 1.5M concurrent connections and pushes over 250,000 messages per second.
This server-side infrastructure has continued to be stable. As we serve newer cities with a wide variety of network conditions and apps, our focus is on continuing to increase the long tail reliability of push message delivery to mobile devices. We are consistently experimenting with new protocols and developing methodologies to bridge gaps. On inspecting the gaps, the following areas are contributing to drop in reliability.
Loss of acknowledgements
The RAMEN protocol defined above was optimized for reducing data transfer and hence acknowledgements were only reported every 30 seconds or when the client reconnected. This results in delayed acknowledgements and in some cases failure to acknowledge a message delivery. This makes it difficult to distinguish between genuine message losses and failure in acknowledgement requests.
Poor connection stability
Maintaining a healthy connection between the server and client is critical. The client implementations across different platforms have many nuanced differences in handling errors, timeouts, backoffs or app lifecycle events (open or close), network state changes, hostname, and datacenter failovers. This results in variability in performance across versions.
Transport limitations
Since the protocol was implemented on SSE, the data transfer is unidirectional. A number of new app experiences required us to enable bidirectional message transfers. Without real-time round trip time measurement, determining network conditions, speed of transfer, and reducing head of line blocking is not feasible. SSE is also a text-based protocol limiting our ability to transfer binary payloads without a text encoding like base64 resulting in larger payload sizes.
In late 2019 we started developing the next generation of the RAMEN protocol to address the above shortcomings. After a lot of consideration, we chose to build this on top of gRPC. gRPC is a widely adopted RPC stack with standardized implementations of client and server across many languages. It has first class support for many different RPC methods and has interoperability with the QUIC transport layer protocol.
The new gRPC-based RAMEN protocol extends from the previous SSE-based protocol with a few key differences:
This work is currently in beta release and the early signals are promising.
The Push platform is an integral part of Uber’s trip experience. Hundreds of features today are powered by this platform. Here are few key reasons why this platform is immensely successful at Uber.
Separation of concerns
The clear separation of responsibilities between the message triggering, creation, and the delivery system allowed us to shift focus on different parts of the platform as the needs of the business changed. Separation of the delivery components into Apache Helix, topology logic and core business logic of streaming are very well separated. This allowed support for gRPC on exactly the same architecture but with different wire protocols.
Industry standard technologies
Building on top of industry standard technologies makes implementation far more robust, long-term, and cost effective. The maintenance overhead of the above system has been very minimal. We are able to deliver this value as a platform with an extremely efficient team size. In our experience, Helix and Zookeeper have been extremely stable.
Simpler design
We could scale to millions of users across varying network conditions, hundreds of features, and dozens of apps with this protocol. The protocol’s simplicity made it easy to scale and move fast.
We would like to thank all the engineers who took on a collaborative effort to build this platform across multiple years. The Edge Streaming team in the Uber Bangalore site is leading the next phase of evolution of this platform. If you’re interested in solving high scalability distributed systems problems that have direct business impact, please apply to join our team.
(Notice: Origin official document is Here